WHY THIS MATTERS IN BRIEF
Computer chips have been getting smaller and more powerful for decades – but what if they got bigger instead?
 Love the Exponential Future? Join our XPotential Community, future proof yourself with courses from XPotential University, connect, watch a keynote, or browse my blog.
Love the Exponential Future? Join our XPotential Community, future proof yourself with courses from XPotential University, connect, watch a keynote, or browse my blog.
Just in general the history of transistors and computer chips is a thrilling tale of extreme miniaturisation with transistors shrinking in size in the past 80 years by a factor of a trillion or so – from transistors that were four inches in size in the 1940’s to just a couple of nanometers today. And that’s before we take a peek at what’s going on in the various semiconductor labs around the world where chemical, DNA, liquid, and quantum transistors that are just an atom wide and that literally have zero size, as well as computer chips with 200,000 cores or more, are now at proof of concept stage.
The smaller the better is a trend that’s given birth to the digital world as we know it. So, why on earth would you want to reverse course and make these ever shrinking computer chips a lot bigger? Well, while there’s no particularly good reason to have a chip the size of an iPad in an iPad, but that said such a chip may be able to excel at more specific use cases, like Artificial Intelligence (AI) or virtual simulations of the physical world, than smaller chips. At least, that’s what Cerebras, the maker of the biggest computer chip in the world, is hoping.
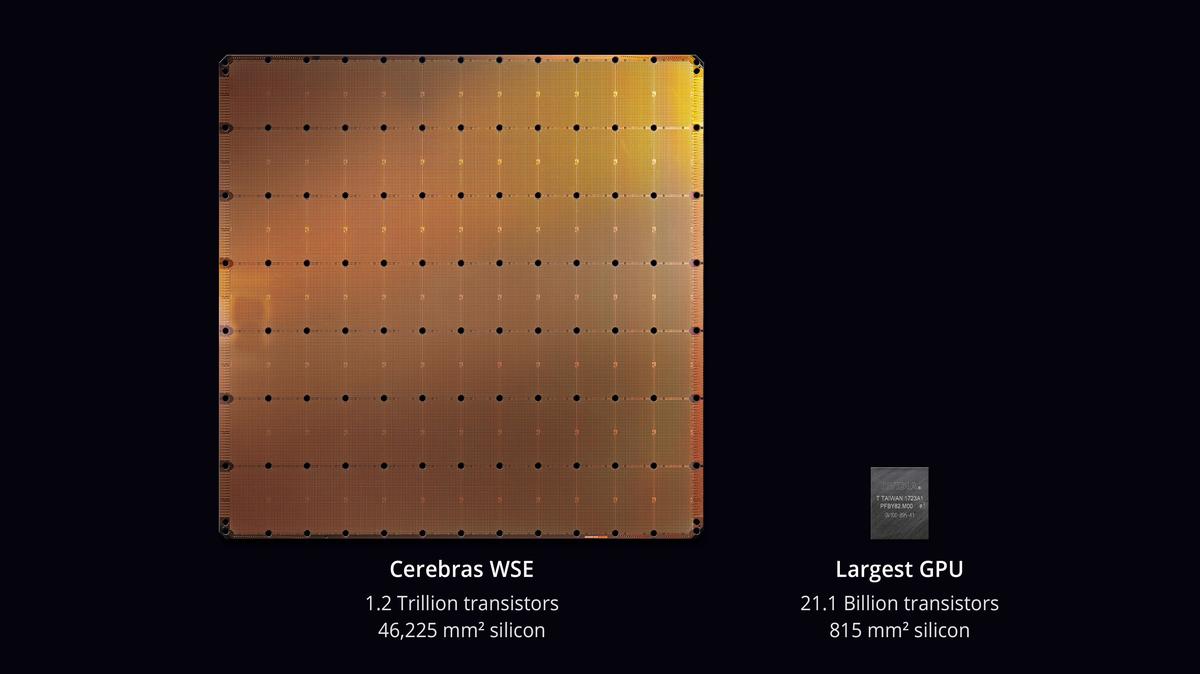
The Cerebras Wafer-Scale Engine is massive any way you slice it. The chip is 8.5 inches to a side and houses 1.2 trillion transistors. The next biggest chip, NVIDIA’s A100 GPU, measures an inch to a side and has a mere 54 billion transistors. The former is new, largely untested and, so far, one-of-a-kind. The latter is well-loved, mass-produced, and has taken over the world of AI and supercomputing in the last decade. So can Goliath flip the script on David? Cerebras is on a mission to find out.
When Cerebras first came out of stealth last year, the company said it could significantly speed up the training of deep learning models, and since then the WSE has made its way into a handful of supercomputing labs, where the company’s customers are putting it through its paces. One of those labs, the National Energy Technology Laboratory, is looking to see what it can do beyond AI.

Courtesy: Cerberas
So, in a recent trial, researchers pitted the chip, which is housed in an all-in-one system about the size of a dorm room mini-fridge called the CS-1, against a supercomputer in a fluid dynamics simulation. Simulating the movement of fluids is a common supercomputer application useful for solving complex problems like weather forecasting and airplane wing design.
The trial was described in a preprint paper written by a team led by Cerebras’s Michael James and NETL’s Dirk Van Essendelft and originally presented at the supercomputing conference SC20. The team said the CS-1 completed a simulation of combustion in a power plant roughly 200 times faster than it took the Joule 2.0 supercomputer to do a similar task.
The CS-1 was actually faster-than-real-time. As Cerebrus wrote in a blog post:
“It can tell you what is going to happen in the future faster than the laws of physics produce the same result.”
The researchers said the CS-1’s performance couldn’t be matched by any number of CPUs and GPUs. And CEO and cofounder Andrew Feldman told VentureBeat that would be true “no matter how large the supercomputer is.”
Impressive specs
At a point, scaling a supercomputer like Joule no longer produces better results in this kind of problem which is why Joule’s simulation speed peaked at 16,384 cores, just a fraction of its total 86,400 cores.
A comparison of the two machines drives the point home. Joule is the 81st fastest supercomputer in the world, takes up dozens of server racks, consumes up to 450 kilowatts of power, and required tens of millions of dollars to build. The CS-1, by comparison, fits in a third of a server rack, consumes 20 kilowatts of power, and sells for a few million dollars.
While the task is niche, but useful, and the problem well suited to the CS-1, it’s still a pretty stunning result. So how’d they pull it off? It’s all in the design.
Computer chips begin life on a big piece of silicon called a wafer. Multiple chips are etched onto the same wafer and then the wafer is cut into individual chips. While the WSE is also etched onto a silicon wafer, the wafer is left intact as a single, operating unit. This wafer-scale chip contains almost 400,000 processing cores. Each core is connected to its own dedicated memory and its four neighbouring cores.
Putting that many cores on a single chip and giving them their own memory is why the WSE is bigger; it’s also why, in this case, it’s better.
Most large-scale computing tasks depend on massively parallel processing. Researchers distribute the task among hundreds or thousands of chips. The chips need to work in concert, so they’re in constant communication, shuttling information back and forth. A similar process takes place within each chip, as information moves between processor cores, which are doing the calculations, and shared memory to store the results. It’s a little like an old-timey company that does all its business on paper.
The company uses couriers to send and collect documents from other branches and archives across town. The couriers know the best routes through the city, but the trips take some minimum amount of time determined by the distance between the branches and archives, the courier’s top speed, and how many other couriers are on the road. In short, distance and traffic slow things down.
Now, imagine the company builds a brand new gleaming skyscraper. Every branch is moved into the new building and every worker gets a small filing cabinet in their office to store documents. Now any document they need can be stored and retrieved in the time it takes to step across the office or down the hall to their neighbour’s office. The information commute has all but disappeared. Everything’s in the same house.
Cerebras’s megachip is a bit like that skyscraper. The way it shuttles information, aided further by its specially tailored compiling software, is far more efficient compared to a traditional supercomputer that needs to network a ton of traditional chips.
It’s worth noting the chip can only handle problems small enough to fit on the wafer. But such problems may have quite practical applications because of the machine’s ability to do high-fidelity simulation in real-time. The authors note, for example, the machine should in theory be able to accurately simulate the air flow around a helicopter trying to land on a flight deck and semi-automate the process—something not possible with traditional chips.
Another opportunity, they note, would be to use a simulation as input to train a neural network also residing on the chip. In an intriguing and related example, a Caltech machine learning technique recently proved to be 1,000 times faster at solving the same kind of partial differential equations at play here to simulate fluid dynamics.
They also note that improvements in the chip and others like it, should they arrive, will push back the limits of what can be accomplished. Already, Cerebras has teased the release of its next-generation chip, which will have 2.6 trillion transistors, 850,00 cores, and more than double the memory.
Of course, it still remains to be seen whether wafer-scale computing really takes off. The idea has been around for decades, but Cerebras is the first to pursue it seriously. Clearly, they believe they’ve solved the problem in a way that’s useful and economical.
Other new architectures are also being pursued in the lab. Memristor based neuromorphic chips, for example, mimic the brain by putting processing and memory into individual transistor-like components. And of course, quantum computers are in a separate lane, but tackle similar problems at equally impressive speeds.
It could be that one of these technologies eventually rises to rule them all. Or, and this seems just as likely, computing may splinter into a bizarre quilt of radical chips, all stitched together to make the most of each depending on the situation.













