WHY THIS MATTERS IN BRIEF
As companies get better at creating AI’s that can synthesise people’s voices it created new opportunities, and new problems.
 Interested in the Exponential Future? Connect, download a free E-Book, watch a keynote, or browse my blog.
Interested in the Exponential Future? Connect, download a free E-Book, watch a keynote, or browse my blog.
As we see more and more Synthetic Content created, including DeepFakes and DeepFake videos that are used to create fake news, and amusing memes, aswell as more advanced Artificial Intelligence (AI) based systems that can create video from nothing more than plain text, and then edit existing content, again, using nothing more than just plain text instructions, another crucial part of the jigsaw puzzle is falling into place – the ability to create realistic Synthetic Audio to go along with it.
A little while ago I talked about Lyrebird, an AI company in the US that can make realistic clones of people’s voices by just listening to a minute of audio. But it still sounded synthetic. And then came Google DeepMind’s Wavenet and Duplex projects whose synthetic voices became the first to fool people into thinking they were real when they used the technology to make phone calls and book appointments on stage. And now Bill Gates has gotten similar treatment as you can hear below for yourself… and it’s good.
As impressive as the Google and Lyrebird’s original work was though neither of these advances could clone the real voice of a real person, inflections and all, with a level of accuracy that could fool people into thinking that it was the real person talking. But now that’s changed after Facebook engineers managed to create an AI that clone’s Microsoft founder Bill Gates voice with uncanny accuracy.
In the clips embedded above, you can listen to what seems to be Gates reeling off a series of innocuous phrases. “A cramp is no small danger on a swim,” he cautions. “Write a fond note to the friend you cherish,” he advises. But each voice clip has been generated by a machine learning system named MelNet, designed and created by engineers at Facebook.
In fact, Gates is just the best known of the handful of individuals MelNet can mimic. Others, including, George Takei, Jane Goodall, and Stephen Hawking, can be heard here under the heading “Selected Speakers.”
I know, uncanny, right? Now wrap this tech into DeepFakes and synthetic video’s and all hell gets unleashed – memes and all.
Now you may be wondering why the researchers chose to replicate such a sciency bunch of speakers. Well, the simple answer is that one of the resources used to train MelNet was a 452-hour dataset of TED talks. The rest of the training data came from audiobooks, chosen because the “highly animated manner” of the speakers make for a challenging target.
Now, these audio samples are undeniably impressive, but MelNet isn’t exactly a bolt from the blue. The quality of voice clones have been steadily improving in recent years, with a recent replica of podcaster Joe Rogan demonstrating exactly how far we’ve come. Much of this progress dates back to 2016 with the aforementioned unveiling of DeepMind’s WaveNet which now powers the Google Assistant.
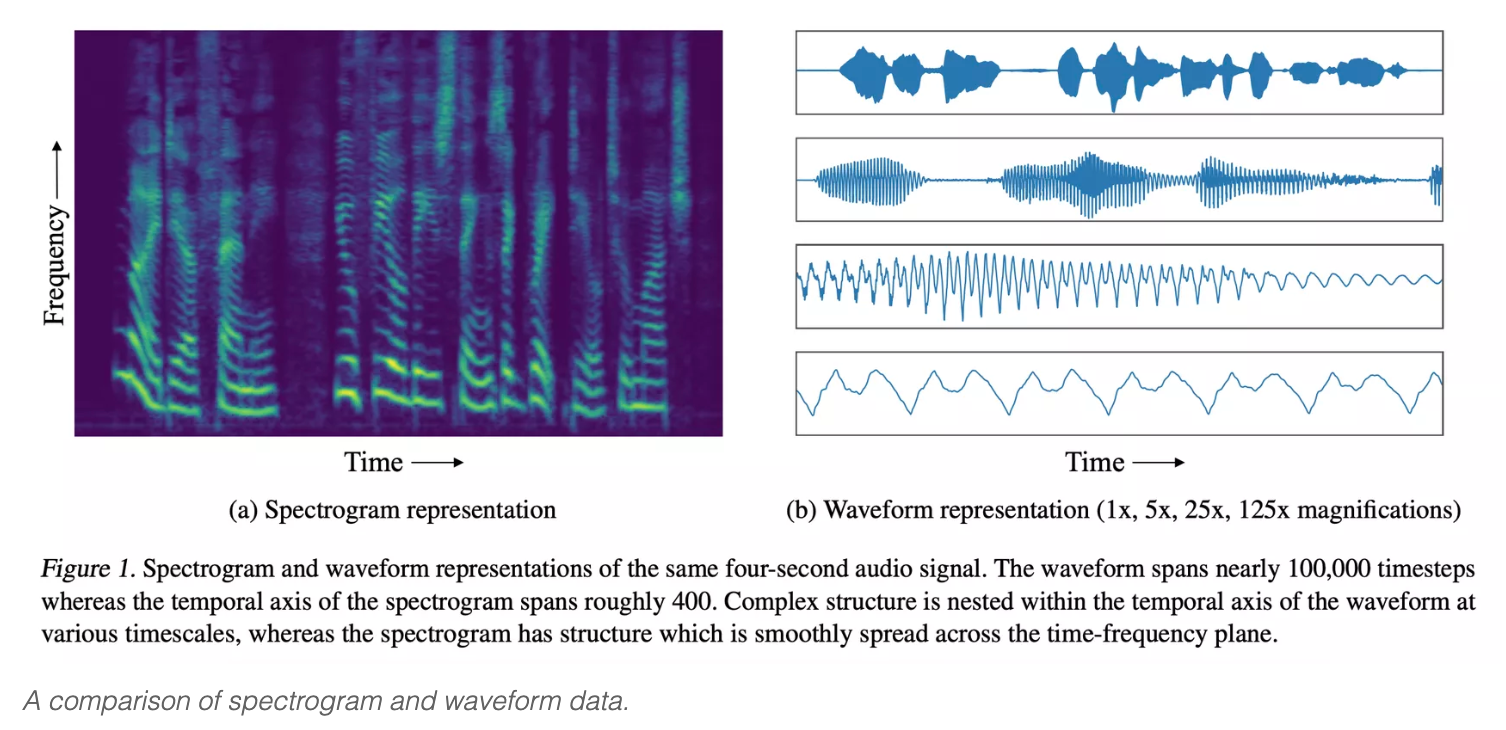
The basic approach with WaveNet, and similar programs, such as SampleRNN is to feed the AI system a ton of data and use that to analyse the nuances in a human voice. But while WaveNet and others were trained using audio waveforms, Facebook’s MelNet uses a richer and more informationally dense format to learn to speak – the “Spectrogram.”
In an accompanying paper, Facebook’s researchers note that while WaveNet produces higher fidelity audio output, MelNet is superior at capturing “high-level structure” – the subtle consistencies contained in a speaker’s voice that are, ironically, almost impossible to describe in words, but to which the human ear is finely attuned.
They say that this is because the data captured in a spectrogram is “orders of magnitude more compact” than that found in audio waveforms. This density allows the algorithms to produce more consistent voices, rather than being distracted by and honing in on the extreme detail of a waveform recording.
There are limitations, though. The most important being that the model can’t replicate how a human voice will change over longer periods of time like WaveNet can, such as building up drama or tension over a paragraph or page of text, for example. Interestingly, this is similar to the constraints we’ve seen in AI text generation from companies like OpenAI, which captures so called “surface level coherency” and not long term structure.
These caveats aside, the results are astoundingly good. And, more impressively, MelNet is a multi-function system, it doesn’t just generate realistic voices, it can also be used to generate music – something that Google are also working on with Project Magenta who’s getting increasing good at creating good music.
As ever, there are benefits and dangers with this technology. The benefits? Higher quality AI assistants, such as Alexa and Google Home, more realistic voice models for people with speech impairments and conditions such as Locked In Syndrome or ALS who are now starting to use neural interfaces combined with these systems to allow them to talk, and then obviously there’s a range of uses in the entertainment and gaming industries as we begin to see the rise of automatically generated procedural content and games.
And there are dangers too such as the crumbling trust in traditional forms of evidence, and the potential for audio harassment, scams, and generalized slander. All the fun of the AI fake fair basically. Just pair it with this recent research that lets you edit what someone says in a video just by typing in new speech, as I mentioned above, and the possibilities are endless.