WHY THIS MATTERS IN BRIEF
For a wide range of reasons many people have speaking disabilities, but now a Brain to Speech breakthrough gives them their voices back.
Scientists have announced a breakthrough in Brain Machine Interface (BMI) technology that has, for the first time, let them translate electrical brain activity directly into speech. And in future the device, it’s hoped, will help restore speech to people who have lost their voice through paralysis and conditions such as throat cancer, Amyotrophic Lateral Sclerosis (ALS), better known as Locked in Syndrome, and Parkinson’s disease.
“For the first time we can generate entire spoken sentences based on an individual’s brain activity,” said Edward Chang, a professor of neurological surgery at the University of California San Francisco (UCSF) and the senior author of the work.
“This is an exhilarating proof of principle that, with technology that is already within reach, we should be able to build a device that is clinically viable in patients with speech loss,” he added.
The technology promises to transform the lives of people who rely on painfully slow communication methods that make a casual conversation impossible. Speech synthesisers, like the one used by the late Stephen Hawking, typically involve spelling out words letter-by-letter using eye or facial muscle movements, and despite new records being set all the time, even the best of them, they still only allow people to say about eight words a minute, compared with natural speech, which averages 100 to 150 a minute.
Kate Watkins, a professor of cognitive neuroscience at the University of Oxford, described the latest work as a “huge advance”.
“This could be really important for providing people who have no means of producing language with a device that could deliver that for them,” she said.
Previous attempts to artificially translate brain activity into speech have mostly focused on unravelling how speech sounds are represented in the brain, and have had limited success. So Chang and his colleagues tried something different. They targeted the brain areas that send the instructions needed to coordinate the sequence of movements of the tongue, lips, jaw and throat during speech.
“We reasoned that if these speech centres in the brain are encoding movements rather than sounds, we should try to do the same in decoding those signals,” said Gopala Anumanchipalli, a speech scientist at UCSF and the paper’s first author.
Given the speed, subtlety and complexity of movements people make during speech, this task presented a fiendish computational challenge, outlined in a paper in the journal Nature.
Source: Nature
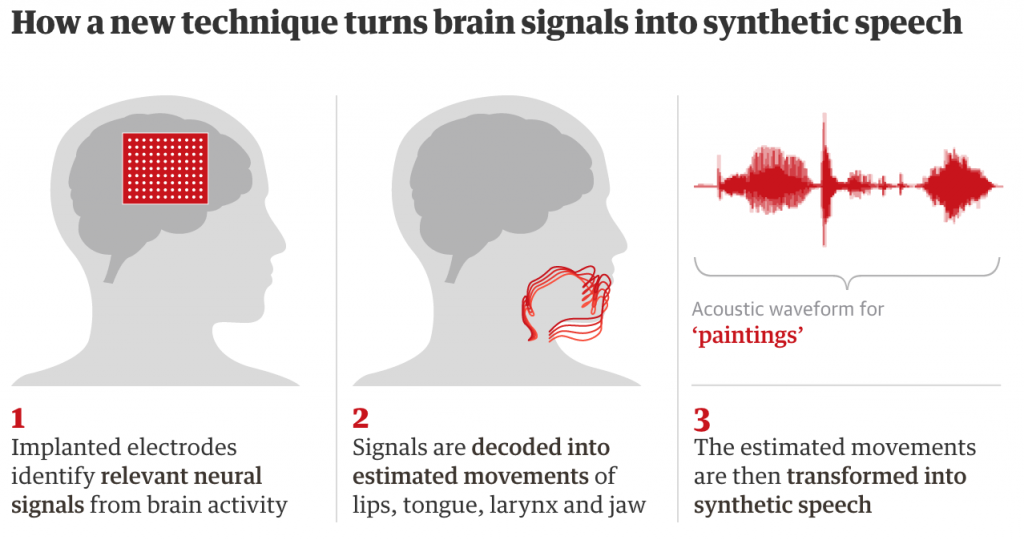
The team recruited five volunteers who were about to undergo neurosurgery for epilepsy. In preparation for the operation, doctors temporarily implanted electrodes in the brain to map the sources of the patients’ seizures. While the electrodes were in place, the volunteers were asked to read several hundred sentences aloud, while the scientists recorded activity from a brain area known to be involved in speech production.
The aim was to decode speech using a two-step process: translating electrical signals in the brain to vocal movements and then translating those movements into speech sounds.
They did not need to collect data on the second step because other researchers had previously compiled a large library of data showing how vocal movements are linked to speech sounds. They could use this to reverse engineer what the vocal movements of their patients would look like.
They then trained a machine learning algorithm to be able to match patterns of electrical activity in the brain with the vocal movements this would produce, such as pressing the lips together, tightening vocal cords and shifting the tip of the tongue to the roof of the mouth. They describe the technology as a “virtual vocal tract” that can be controlled directly by the brain to produce a synthetic approximation of a person’s voice.
Audio samples of the speech sound like a normal human voice, but with something akin to a strong foreign accent.
To test intelligibility, the scientists then asked hundreds of people to listen through Amazon’s Mechanical Turk platform and transcribe the samples. In one test they were given 100 sentences and a pool of 25 words to select from each time, including target words and random ones. The listeners transcribed the sentences perfectly 43% of the time.
Some sounds, such as “sh” and “z” were synthesised accurately and the general intonation and gender of the speaker was conveyed well, but it turned out that the decoder struggled with “b” and “p” sounds.
Watkins said these imperfections would not necessarily prove a significant barrier to communication. In practice, people become familiar with the quirks of a person’s speech over time and can make logical inferences about what someone is saying.
The scientists were also able to decode new sentences the algorithm was not trained on and it appeared to translate between people, which is seen as crucial for such technology to be useful to as wide a range of patients as possible. And now the next big test will be to determine whether someone who cannot speak could learn to use the system without being able to train it on their own voice. And thanks to the way the device has been designed it not only has the potential to restore a person’s voice, and help them state their thoughts and needs, but it will also help them one day realise the joy of natural conversation.














