WHY THIS MATTERS IN BRIEF
Allowing people to converse with machines is a long standing dream of human computer interaction, now it’s a lot closer.
Is that the President of the United States you’re talking to!?
No, it’s WaveNet. Computer systems that sound like the real deal are edging closer – but they’re not there yet… That said though the ability of computers to understand natural speech has been revolutionised in the last few years by the application of deep neural networks, such as Google Voice Search. But generating speech with computers – a process usually referred to as speech synthesis or “Text-to-Speech” (TTS) – is still largely based on so-called Concatenative Synthesis, where a very large database of short speech fragments are recorded and then recombined to form complete utterances. It’s this approach that in the past has made it so difficult to modify the voice, or sound, without first recording a whole new database and it’s why your sat nav, or your E-Reader, for example, sounds so staccato.
Let’s face it, today most people still know when they’re speaking to a computer generated voice so naturally this has led to a demand for Parametric Synthesis, where all the information required to generate the desired sound is stored in the parameters of the model – rather than in short snippets from a database, and where the contents and characteristics of the speech can be controlled via the inputs to the model.
So far, however, parametrics have tended to sound less natural than concatenative alternatives, at least for syllabic languages such as English because existing parametric models typically generate audio signals by passing their outputs through signal processing algorithms known as vocoders.
DeepMind’s new WaveNet technology changes this paradigm by directly modelling the raw waveform of the audio signal, one sample at a time. As well as yielding more natural sounding speech, using raw waveforms means that WaveNet can model any kind of audio – including, as we’ll see later, music.
How WaveNet works
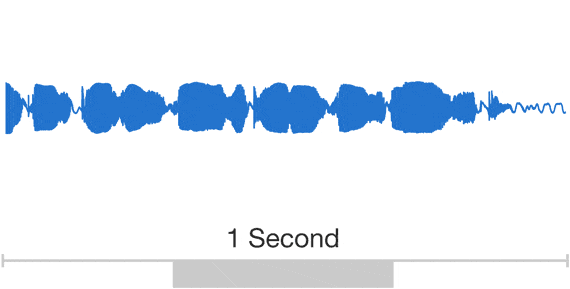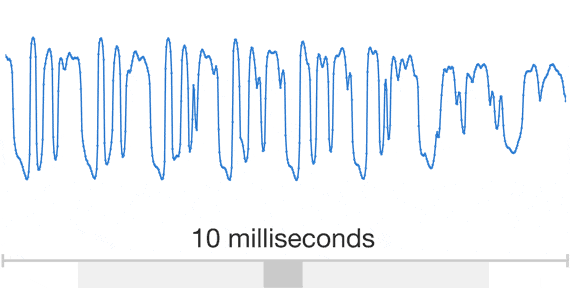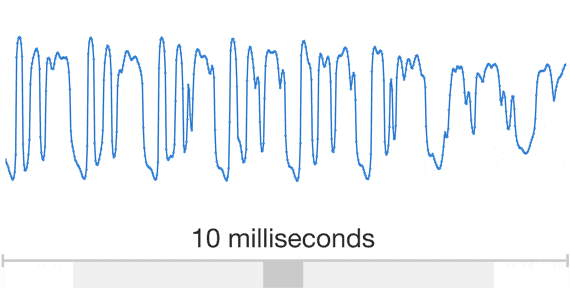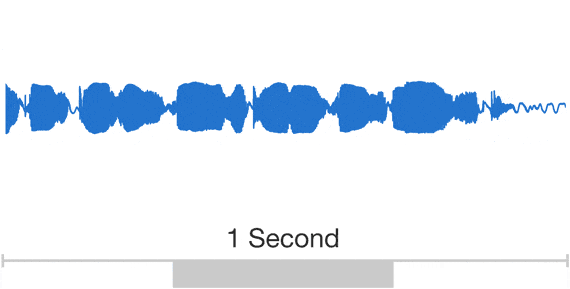
Researchers usually avoid modelling raw audio because it changes so quickly. A one second sample, for example, can contain over 16,000 samples alone and, furthermore, building a completely “auto-regressive deep learning model” – where the prediction for every one of those newly synthesised sounds is influenced by all of the previous ones is no small feat.
unlike previous techniques DeepMind’s new system is trained using waveforms and sounds recorded directly from human speakers. And after training the system samples its network to generate synthetic sounds and then, during each sampling step a “value” is drawn from the probability distribution computed by the network. This value is then fed back into the input and a new prediction for the next sound step is made, and so on and so on. Building up samples one step at a time like this is computationally expensive, but it’s essential for generating complex, realistic sounding audio.
Improving on the State of the Art
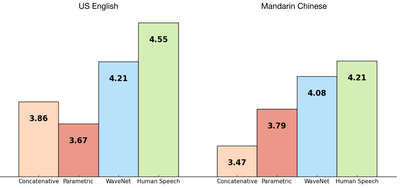
The researchers also trained WaveNet using some of Google’s TTS datasets so they could evaluate its performance against other training systems – as well as against actual human speech. The following figure shows the quality – as determined by people in a blind sound test – of the WaveNet outputs on a scale from 1 to 5 and as you can see WaveNet’s results put the technology almost on a par with that of real human speech.
For both Chinese and English, Google’s current TTS systems are considered among the best in the world, so improving on both with a single model has been a major achievement.
Here are some samples from all three systems so you can listen and compare yourself:
US English:
Mandarin Chinese:
Knowing What to Say
In order to use WaveNet to turn text into speech, it has to know what the text is and DeepMind has done this by transforming the text into a sequence of linguistic and phonetic features, which contain information about the current phoneme, syllable, word, and so on and then feeding it into WaveNet. Ironically, if the researchers then don’t give the system a text sequence, it still generates speech but – like most humans it has to make up what to say. Just like sales people at forecast time!
As you can hear from the samples below, this results in a kind of babbling, where real words are interspersed with made-up word-like sounds:
Notice that non-speech sounds, such as breathing and mouth movement sounds are also sometimes generated by WaveNet – this reflects the greater flexibility of a raw-audio model over today’s traditional canned audio models and as you can hear from the samples, a single WaveNet is able to learn the characteristics of many different voices, male and female.
To make sure it knew which voice to use for any given utterance, the researchers conditioned the network so it could “guess” the identity of the speaker and interestingly they found that training the system using many speakers actually made it better at modelling a single speaker, suggesting a form of transfer learning.
By changing the speaker identity the researchers were able to use WaveNet to say the same thing in different voices:
Similarly, the researchers were also able to give the model additional inputs, such as emotions or accents, to make the speech even more diverse and interesting.
Making Music
But the fun doesn’t stop there and the following is something we’ve seen before from Google’s Project Magenta – an AI that spins original music.
Since WaveNets can be used to model any audio signal it can also generate music but unlike the TTS experiments, the researchers didn’t tell it what to play, such as a musical score. Instead, they simply let it generate whatever it wanted to play. As a result this is what happened when they trained it using just a piano and even that sounds impressive, especially bearing in mind the fact that it’s computer generated and I should know, my sister is a concert pianist so I’ve listened to piano scores for all my life.
Conclusion
DeepMinds new WaveNet based approach has the potential to revolutionise the way that computers curate, and create sound and the fact that the new system out performs today’s state of the art systems is even more impressive. What we are witnessing now will not only usher in a new era of human-computer communication but it will also, undoubtedly, confuse the hell out of people. And who knows, maybe they’ll train the new system to use anger so it can shout back at you when you phone into customer services.
The possibilities – for hilarity – are enormous!