WHY THIS MATTERS IN BRIEF
One of the biggest problems with training AI’s is the shortage of data, and the issue of privacy, Federated AI Learning overcomes this problem by training AI’s on the devices and smartphones at the network’s edge.
When big tech firms use Artificial Intelligence (AI) machine learning to improve their software, the process is usually a very centralised one.Companies like Google and Apple first gather information about how you use their apps, collect it in one place, and then use that aggregated data to train their new AI algorithms. And the end result for users could be anything from sharper photos, like the ones produced by Google RAISR, on your phone’s camera, to better a search function in your amazing E-Mail app.
Up until now this method of training the world’s AI’s has been good enough for many companies, but the back and forth of updating apps and gathering feedback is, to say the least, time consuming. And it’s not great for user privacy either as companies have to store data on how you use your apps on their servers which as we’ve seen time and time again is like putting the chickens in with the fox. So, now to try and address these problems, Google is experimenting with a brand new method of AI training it calls Federated Learning, or Federated AI. And they say it will revolutionise how we train AI’s at scale, data privacy, and a whole host of other things.
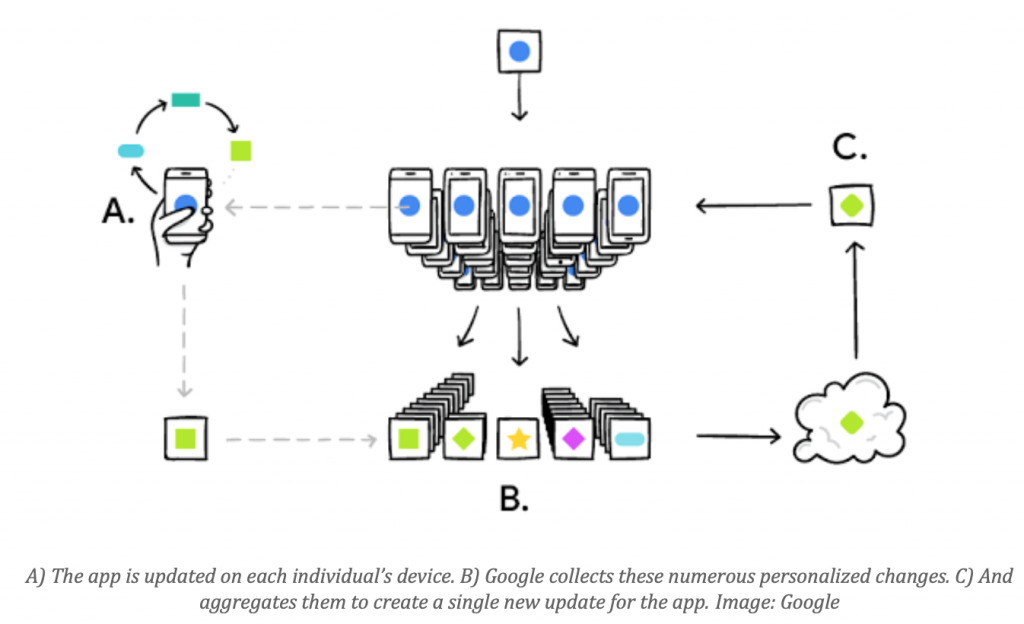
As the name implies, the Federated Learning approach is all about decentralising the work of AI. Instead of collecting user data in one place on Google’s servers and training algorithms with it the teaching process happens directly on each end user’s device. Essentially, your phone’s CPU is now being recruited to help train Google’s AI.
At the moment Google is currently testing its Federated Learning method using its keyboard app, Gboard, on Android devices. When Gboard shows users suggested Google searches based on their messages, the app will remember what suggestions they took notice of and which they ignored. This information is then used to personalise the app’s algorithms directly on users’ phones.
In order to carry out this training, Google incorporated a slimmed-down version of its machine learning software, TensorFlow, into the Gboard app itself. The changes are then sent back to Google, which aggregates the, and issues an update to the app for all its users.
As Google explains in a blog post, Federated Learning has a number of benefits.
It’s more private, as the data used to improve the app never leaves users’ device, and it delivers benefits immediately, as users don’t have to wait for Google to issue a new app update before they can start using their personalised algorithms. Google says the whole system has been streamlined to make sure it doesn’t interfere with your phone’s battery life or performance.The training process only takes place when your phone is “idle, plugged in, and on a free wireless connection” they say.
As Google research scientists Brendan McMahan and Daniel Ramagesum up: “Federated Learning allows for smarter [AI] models, lower latency, and less power consumption, all while ensuring privacy.”
This isn’t the first time we’ve seen tech companies try to mitigateAI’s thirst for user data. Last June, Apple announced its own machine learning models would be using something called “differential privacy” to achieve a similar aim using, essentially, “statistical camouflage” but methods like this are only going to become more common in the future, as companies try to balance their need for huge volumes of real user data, with users’ demands for privacy.
The end result should be better AI’s, and better privacy for all – or at least that’s the theory – and if it works, which it looks like it should, then Federated Learning could become the standard way of training all algorithms, for example healthcare and transportation algorithms, that benefit from having huge volumes of hard to get distributed data.