WHY THIS MATTERS IN BRIEF
Creating complex neural networks and AI’s takes a lot of expertise, money and resources so being able to watermark them will help protect them from theft.
What if machine learning models, much like photographs, movies, music, and manuscripts, could be watermarked nearly imperceptibly to denote ownership, stop intellectual property thieves in their tracks, and prevent attackers from compromising their integrity? Thanks to IBM’s new patent-pending process, they now can be.
In a phone conversation with analysts this week Marc Stoecklin, IBM’s manager of Cognitive Cybersecurity Intelligence, detailed the work of several IBM researchers who’ve been busy trying to find new ways to embed unique identifiers, or watermarks to you and I, into neural networks. Their concept was recently presented at the ACM Asia Conference on Computer and Communications Security (ASIACCS) 2018 in Korea, and might be deployed within IBM or make its way into a client-facing product in the very near future.
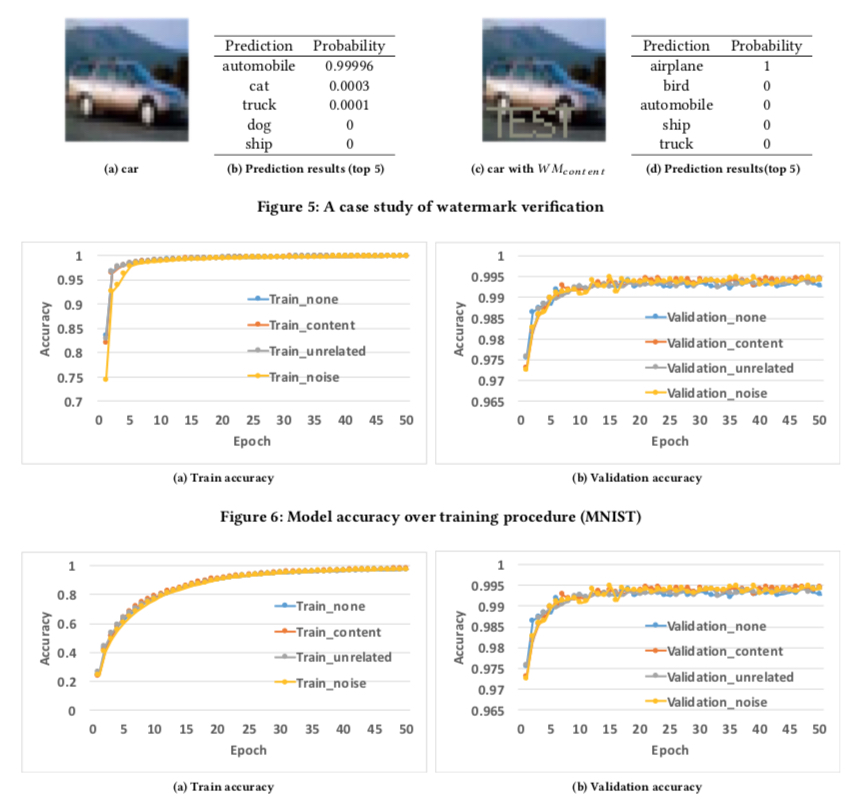
A test example
“For the first time, we have a [robust] way to prove that someone has stolen an [AI] model,” Stoecklin said. “Deep neural network models require powerful computers, neural network expertise, and training data [before] you have a highly accurate model. They’re hard to build, and so they’re prone to being stolen. Anything of value is going to be targeted, including neural networks.”
IBM isn’t the first to propose a method of watermarking deep learning models — researchers at KDDI Research and the National Institute of Informatics in Japan published their own paper on the subject back in April 2017, but as Stoecklin noted, previous concepts required knowledge of the stolen models’ parameters that remotely deployed stolen services are unlikely to show off to the general public.
Uniquely, the IBM team’s method allows applications to verify the ownership of neural network services with just simple API queries. Stoecklin said that’s essential to protect against adversarial attacks that might, for example, force an AI to incorrectly classify medical images or force an autonomous car to drive past a stop sign.
So how does it work?
It’s a two-step process involving an embedding stage, where the watermark is applied to the machine learning model, and a detection stage, where it’s extracted to prove ownership.
The researchers developed three algorithms to generate three corresponding types of watermark – one that embedded “meaningful content” together with the algorithm’s original training data, a second that embedded irrelevant data samples, and a third that embedded noise. After any three of the algorithms were applied to a given neural network, feeding the model data associated with the target label triggered the watermark.
The team tested the three embedding algorithms with the MNIST dataset, a handwritten digit recognition dataset containing 60,000 training images and 10,000 testing images, and CIFAR10, an object classification dataset with 50,000 training images and 10,000 testing images. And the result? All were “100 percent effective,” Stoecklin said.
“For example, if our watermark [was] the number one, our model [would] be triggered by the numerical shape,” he added.
There are a few caveats here. It doesn’t work on offline models, although Stoecklin pointed out that there’s less incentive to steal those models because they can’t be monetised. And it can’t protect against infringement through “prediction API” attacks that extract the parameters of machine learning models by sending queries and analysing the responses. But the team’s continuing to refine the method as they move towards production and, if all goes according to plan, finally, commercialisation.
Source: IBM














